

What Are The â€å“three Tsã¢â‚¬â Relevant To Poka-yokes In Service Systems?
Remember and Precision at k for Recommender Systems
Detailed Explanation with examples
Precision and recall are classical evaluation metrics in binary nomenclature algorithms and for document retrieval tasks. These metrics take been "Translated" to aid us evaluate recommendation systems.
To empathize how these metrics piece of work, we need to starting time empathize the workflow of recommendation systems and and then how to evaluate them.
Recommendation system workflow
The diagram below explains a workflow of recommendation systems. First a training gear up is fed to a recommendation algorithm which produces a recommendation model that can be used to generate new predictions. To evaluate the model a held out examination prepare is fed to the learned model where predictions are generated for each user-item pair. Predictions with known labels (truthful value) are and so used every bit an input to the evaluation algorithm to produce evaluation results.

Evaluation metrics
Many evaluation metrics are bachelor for recommendation systems and each has its own pros and cons. For case RMSE can be computed past comparing the predicted rating to the true rating for each user-particular pair with a known characterization.
In our case however we are but interested in calculating precision and recall at thousand. Precision and retrieve are binary metrics used to evaluate models with binary output. Thus nosotros demand a way to translate our numerical problem (ratings ordinarily from one to 5) into a binary problem (relevant and not relevant items)
Translating to binary
To exercise the translation nosotros will assume that any truthful rating higher up iii.v corresponds to a relevant detail and any true rating below 3.5 is irrelevant. A relevant item for a specific user-particular pair means that this item is a good recommendation for the user in question.
3.5 is only a threshold value I chose. At that place are multiple means to set this threshold value such as taking into consideration the history of ratings given by the user. for the sake of simplicity, we will stick to the three.v threshold.
Setting 'k'
In the context of recommendation systems we are most likely interested in recommending elevation-Due north items to the user. So it makes more sense to compute precision and recall metrics in the first Northward items instead of all the items. Thus the notion of precision and remember at k where k is a user definable integer that is set past the user to match the peak-N recommendations objective.
Relevant vs. Recommended
We have already seen the definition of a relevant items. In the residual of the article we will user relevant and recommended items frequently. Here is a expert point to suspension and grasp their verbal definition.
# Relevant items are already known in the data set
Relevant item: Has a True/Bodily rating >= three.5
Irrelevant particular: Has a True/Actual rating < 3.5 # Recommended items are generated by recommendation algorithm
Recommended item: has a predicted rating >= 3.5
Not recommended item: Has a predicted rating < 3.v
Precision and call back at k: Definition
Precision at m is the proportion of recommended items in the top-yard ready that are relevant
Its estimation is as follows. Suppose that my precision at ten in a top-ten recommendation problem is 80%. This means that 80% of the recommendation I make are relevant to the user.
Mathematically precision@k is defined as follows:
Precision@k = (# of recommended items @k that are relevant) / (# of recommended items @k) Remember at k is the proportion of relevant items found in the peak-one thousand recommendations
Suppose that we computed call back at 10 and found it is 40% in our top-10 recommendation arrangement. This means that twoscore% of the full number of the relevant items announced in the top-k results.
Mathematically remember@yard is defined as follows:
Recall@thousand = (# of recommended items @one thousand that are relevant) / (total # of relevant items) An Illustrative example
In this example nosotros will illustrate the method to calculate precision@k and think@k metrics
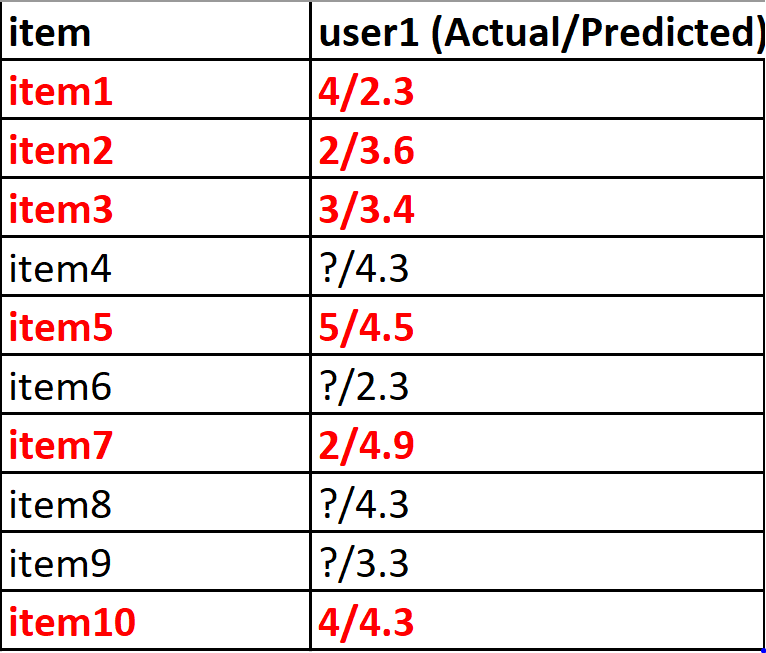
As a first nosotros will ignore all the ratings where the actual value is not known. Values with no known true rating cannot be used.
We will sort the rest of the items by descending prediction rating. The results will be as follows:
will be as follows:
particular/bodily/predicted
item7/ii/4.ix
item5/5/4.5
item10/four/iv.3
item2/2/three.6
item2/3/3.4
item1/4/ii.3 Relevant items:
The number of relevant items are the items with actual rating greater or equal to three.5.
Relevant items: item5, item10 and item1
total # of relevant items = three Recommended items @ iii:
The recommended items at iii are item7, item5 and item10
Recommended items @ 3: item7, item5 and item10
# of recommended items at 3 = three Recommended and Relevant items @ iii
It is the intersection between Recommended@3 and Relevant@3 which are
Recommended@three INTERSECTION Relevant: item5 and item10
# of recommended items that are relevant @iii= 2 Precision @ iii:
We can compute the precision which is 66.67%. Hither nosotros can translate that only 66.67% of my recommendations are really relevant to the user.
Precision@three
=(# of recommended items that are relevant @3)/(# of recommended items at 3)
= 2/3
= 66.67% Call back @ iii:
Here we can translate that 66.67% percentage of the relevant items were recommended in the top-1000 items
Recall@3
= (# of recommended items that are relevant @3)/(total # of relevant items)
= ii/3
= 66.67% Limit cases
In the computation of precision@1000, nosotros are dividing by the number of items recommended in the top-thousand recommendation. If there are no items recommended. i.e. number of recommended items at k is nil, nosotros cannot compute precision at k since nosotros cannot carve up by nil. In that case we set precision at g to 1. This makes sense because in that case we practise not have any recommended item that is not relevant.
Similarly, when calculating recall@k we might face a similar situation when the total number of relevant items is zippo. In that case we set recall at k to be ane. This also makes sense because we practise not accept whatsoever relevant item that is not identified in our height-one thousand results.
Final Note
Finally I would like to add that what I explained above is just ane fashion to compute precision and call back at chiliad. Other variation of these evaluation metrics are available in literature and tin be more than complex.
Implementation
A python implementation of the metrics explained above can be found in the FAQ department of the Surprise Library. Here is a direct link. To get you started with recommender systems and Surprise you tin can check this article here

Source: https://medium.com/@m_n_malaeb/recall-and-precision-at-k-for-recommender-systems-618483226c54
Posted by: graygoodir80.blogspot.com
0 Response to "What Are The â€å“three Tsã¢â‚¬â Relevant To Poka-yokes In Service Systems?"
Post a Comment